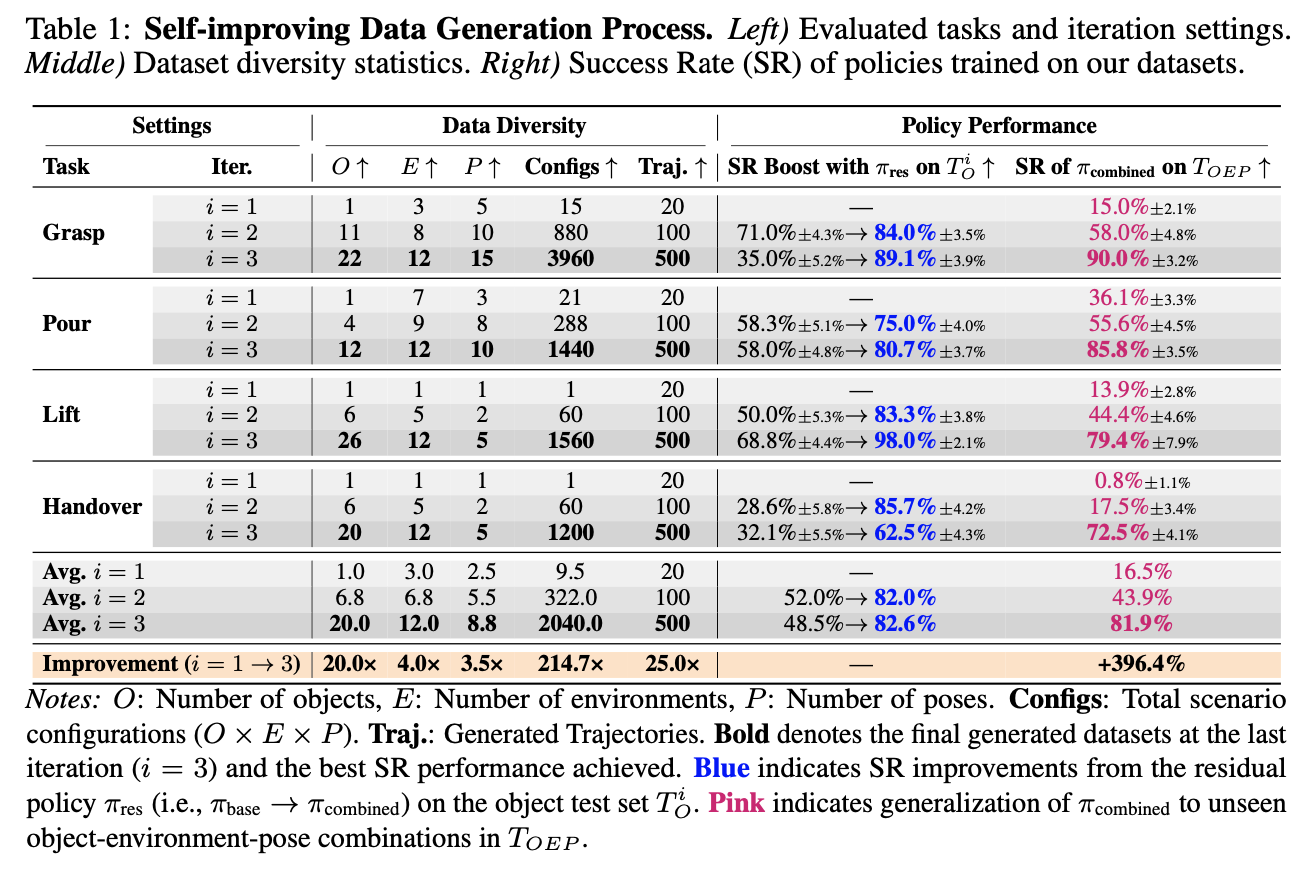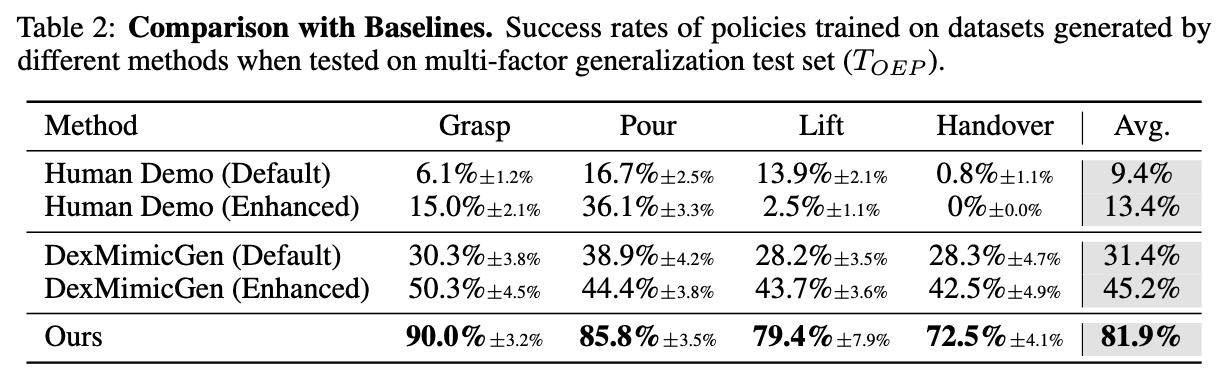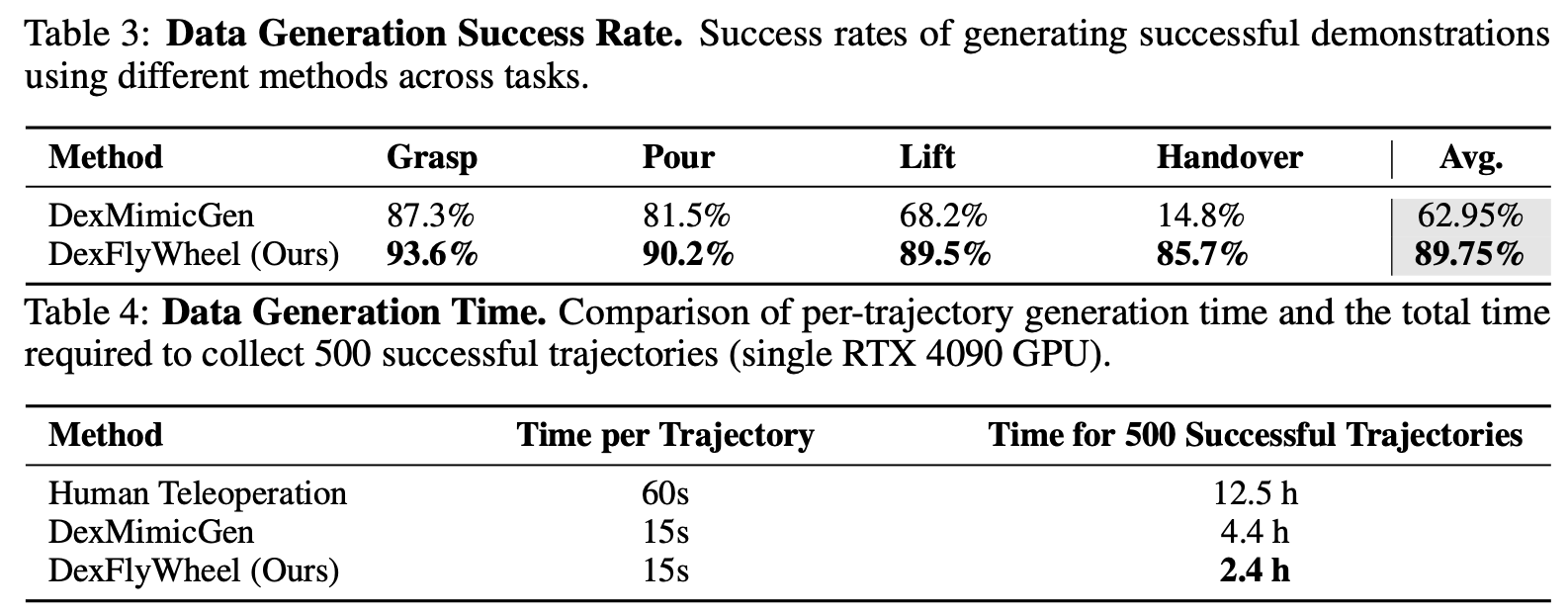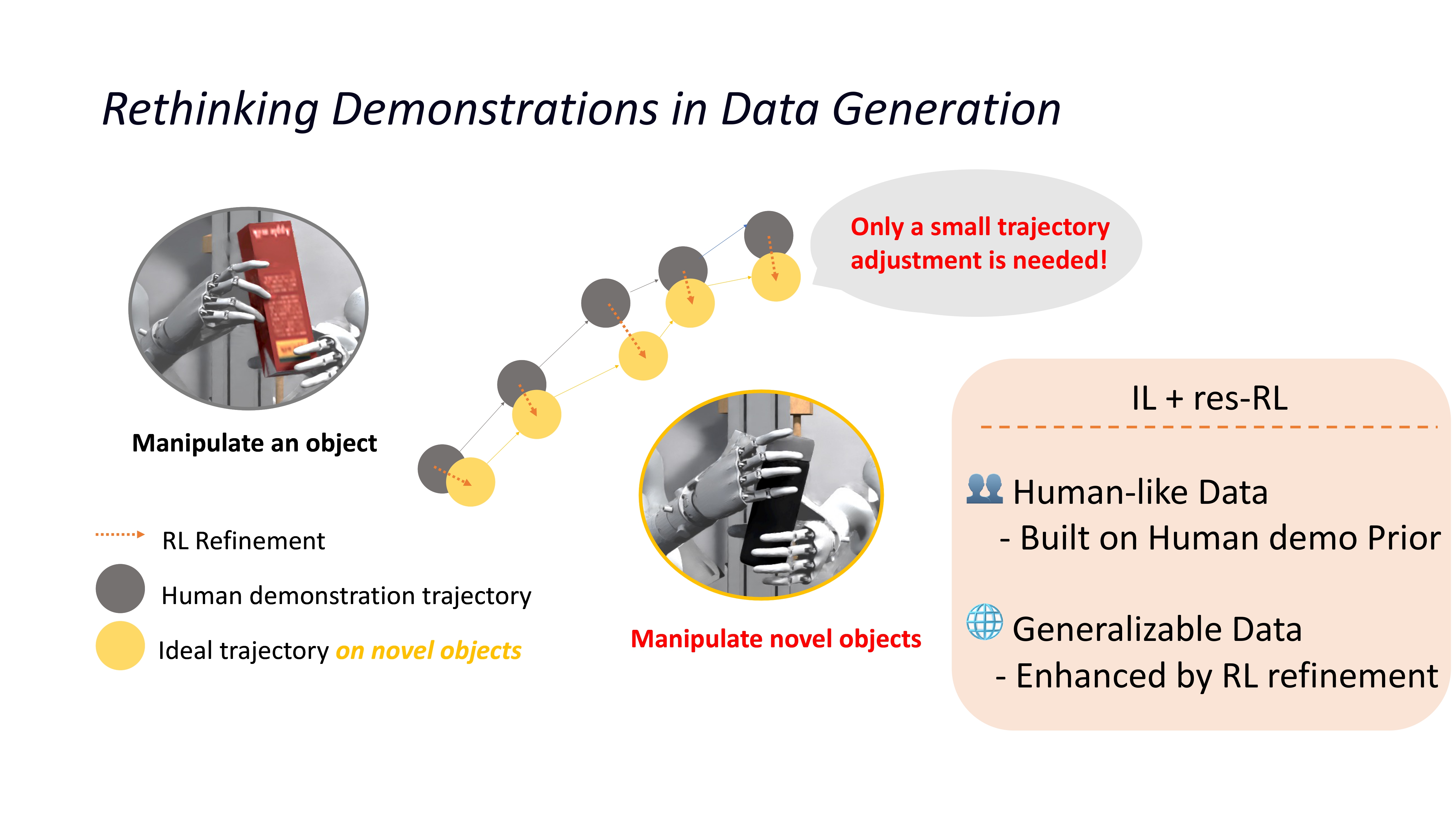
Existing methods are inherently constrained by their source human demonstrations, suffering from limited diversity when handling different objects. This motivates us to rethink the role of human demonstrations in data generation pipelines. We observe that manipulating different objects only induces minor changes in the manipulation trajectories. This implies that Human demonstrations provide a strong behavioral prior in data generation. Imitation learning (IL) uses it to imitate human-like trajectories. Residual reinforcement learning (res-RL) further refines these priors to handle diverse objects scenarios.
To achieve generalizable dexterous manipulation in the open world, robots need a mechanism for continuous data collection and policy performance improvement. This inspires us to build a data flywheel that enables continuous self-improvement, where better policies generate more diverse data, and enhanced data leads to more generalizable policies.